
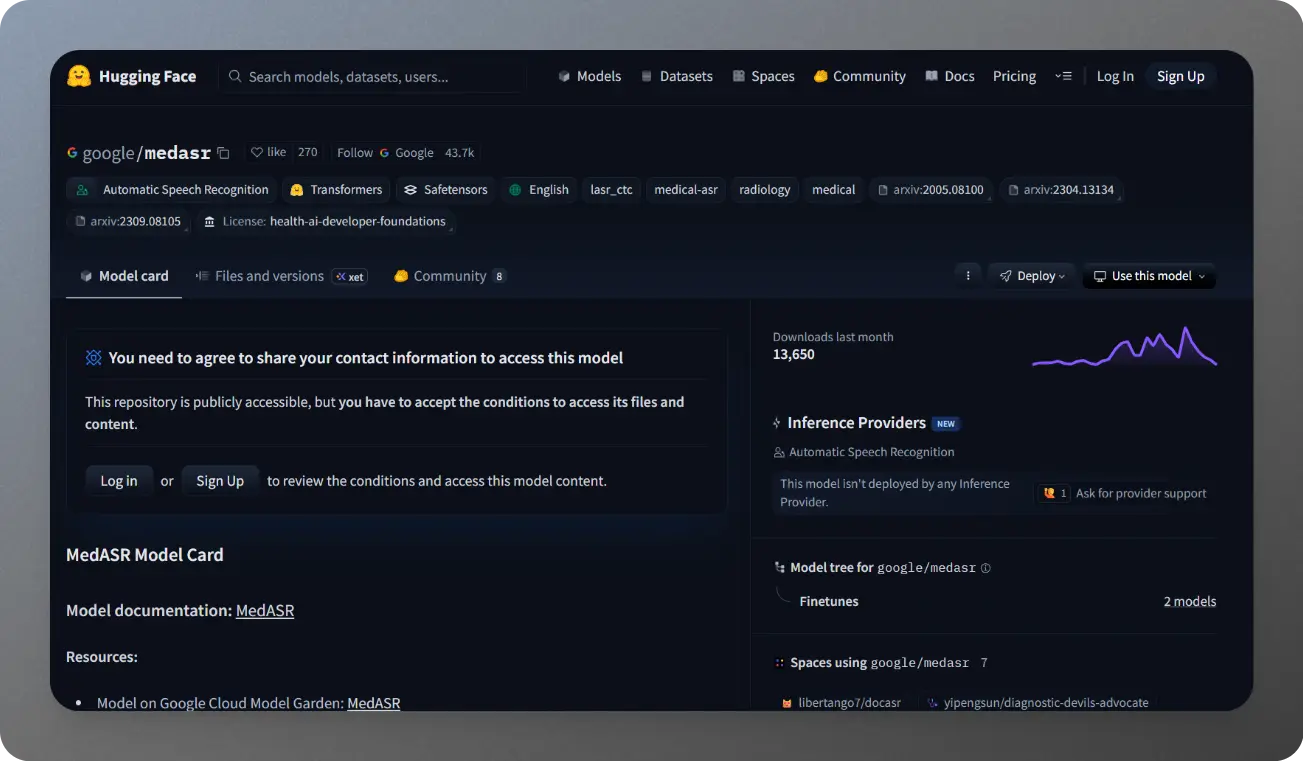
Lyria 3 AI Music Generator
Category: Audio, Social Media
Lyria 3 AI Music Generator is a next-generation multimodal music model designed to transform text, images, and video inputs into…
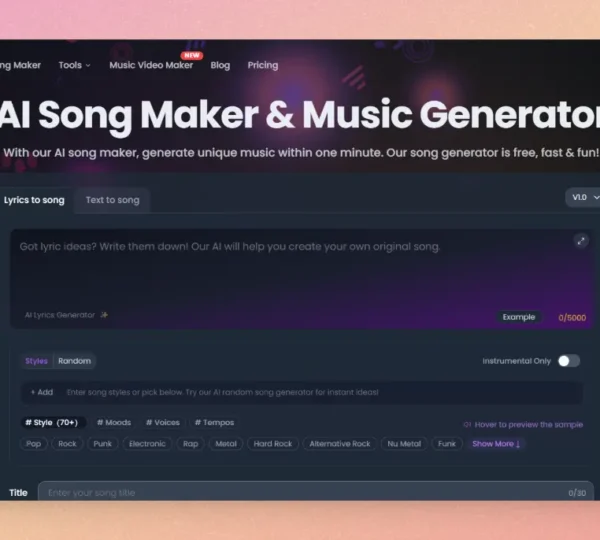
AI Make Song
Category: Audio
AI Make Song – Fast & Free AI Song Maker AI Make Song is a fast, free AI song generator…
Price starts from Free
AiMusic.so
Category: Audio
AiMusic.so – Turn ideas into professional music, lyrics, and videos AiMusic.so is an all-in-one AI music creation platform that helps…
Price starts from Free

Blabby AI
Blabby AI – Voice-to-Text Writing Assistant Blabby AI is an advanced speech-to-text tool for Chrome and Windows that lets you…
Price starts from Freemium
MusicHero AI
Category: Audio
MusicHero.ai – Free AI Music Generator from Text MusicHero.ai lets you create professional-quality songs from simple text descriptions, that too…
Price starts from Free